Tool use
"Tool use" is the mechanism that lets an agent actually do things in the real world. The model never touches anything directly. It asks: "I'd like to call this tool with these arguments." Your harness runs the tool, hands back the result, and the model reads it. That back-and-forth is the whole game. Getting the details right here, how you describe tools, how you handle errors, how you structure results, is the single most leveraged thing you can do for agent reliability.
The contract. Three things that define a tool.
Every tool you expose to Claude is defined by three pieces. Get all three right and the model uses it well. Get one wrong and the tool becomes invisible, or worse, a source of bugs.
- Name. A short, specific identifier like
web_searchorread_file. Matters less than you'd think. - Description. Plain English. Says what the tool does, when to use it, and when not to. This is the single biggest lever on tool-use quality.
- Input schema. A JSON schema listing the arguments. Types, requireds, defaults, descriptions per field.
The model decides whether to call a tool based almost entirely on the description. A vague description ("helps with searching") produces a tool the model either ignores or misuses. A precise description ("searches the user's email inbox. Use when the question is about recent messages or a specific sender") produces a tool used correctly nearly every time. Description quality beats tool name, beats even having the right tools at all.
How the loop runs. Turn by turn.
The loop is simple. It's your job to make sure each step is correct: the tool definitions are clear, the model's request is valid, the harness executes cleanly, and the result is readable. Fails at any stage and the whole thing stalls.
Parallel tool calls: huge latency win.
Modern Claude can request multiple tools in one turn. If your harness is set up to run them in parallel (not sequentially), you get massive latency wins on any task that needs multiple independent lookups.
// Model emits in one turn:
[tool_use: search("MCP spec")]
[tool_use: search("MCP vs API")]
[tool_use: fetch_url("https://modelcontextprotocol.io")]
// Harness runs all three concurrently, returns all three
// results in the next turn. 3x faster than sequential.Don't serialize tool calls by default. If your tools are independent (no side effects, no ordering dependencies), run them in parallel. The user-visible latency on multi-lookup tasks drops by 50-70%.
Error handling. Where most agent reliability comes from.
Tools fail. Network dies. Files don't exist. Credentials expire. The ONE THING that separates a flaky agent from a reliable one is how errors are reported back to the model. A bad error handler causes infinite loops; a good one causes graceful recovery.
// Bad (model just retries):
"Error: ENOENT /path/to/file.txt"
// Good (model can recover):
{
"status": "error",
"error_type": "not_found",
"message": "File /path/to/file.txt does not exist",
"suggestion": "Check the path; list the directory first to see what's there."
}The model reads the "good" version and takes a smarter next step (list the directory). With the "bad" version, the model has no signal about what went wrong, so it just retries. This is the single cheapest reliability upgrade you can make to an agent.
Writing input schemas that actually work.
- Be strict about required vs optional. If a field is required, mark it required. Otherwise the model will hallucinate defaults that feel right but are wrong.
- Enums over free strings. If there are three valid values for a field, declare them as an enum. Prevents typos and wrong-variant calls.
- Descriptions on every field. Not just on the tool itself, on each argument. "query: the search query, plain English, not keywords" is much better than just "query: string."
- Include example calls in the tool description. "Example: search({query: 'prompt caching pricing'})" gives the model a pattern to copy. Huge help.
- Limit nesting. Deep nested JSON schemas confuse the model. Flat is better. Break complex inputs into multiple tools if needed.
The common failure modes, and how to fix each.
Every one of these happens. The fixes are small and concrete. The pattern is: the harness is not just a runner, it's a coach. Clear errors, clear validation, clear retry policy - the agent gets noticeably smarter.
The mental model that makes this click.
Think of tool definitions as microservices. The description is the API doc. The input schema is the OpenAPI contract. The error handling is the status code + body. Write them with the same care you'd write a service other engineers would consume, because the model is exactly that: another engineer reading your API and deciding whether it fits their needs.
Spend the time on descriptions. Spend the time on error messages. Spend the time on schema clarity. It's not glamorous. It's the difference between an agent that works and an agent that kind of works.
Pair this with MCP.
Everything on this page applies equally when the tools come from an MCP server instead of being defined directly in your code. MCP is, mechanically, a standardized way to deliver tool definitions and run tool calls. The description-quality principle, the error-handling principle, the parallel-execution principle, they all apply verbatim.
If you're designing an MCP server, this page doubles as your design guide. The same tools-as-microservices framing applies.
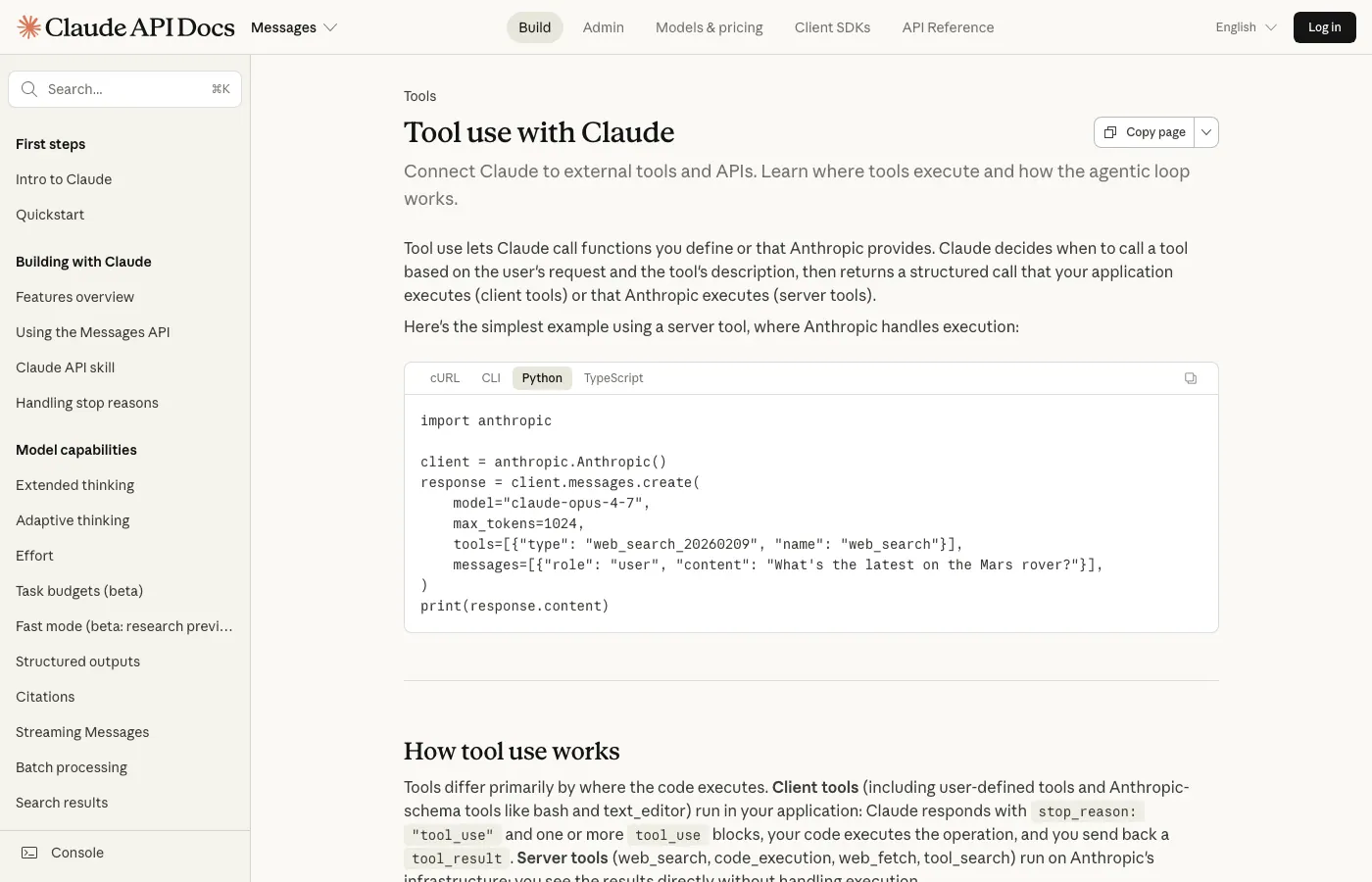
Further reading
- Claude API - Getting started
- Claude - Model overview
- Claude - Tool use
- Claude - Extended thinking
- Claude - Prompt engineering guide
- Anthropic Cookbook - Examples
Watch
Andrej Karpathy - State of GPT (Microsoft Build)